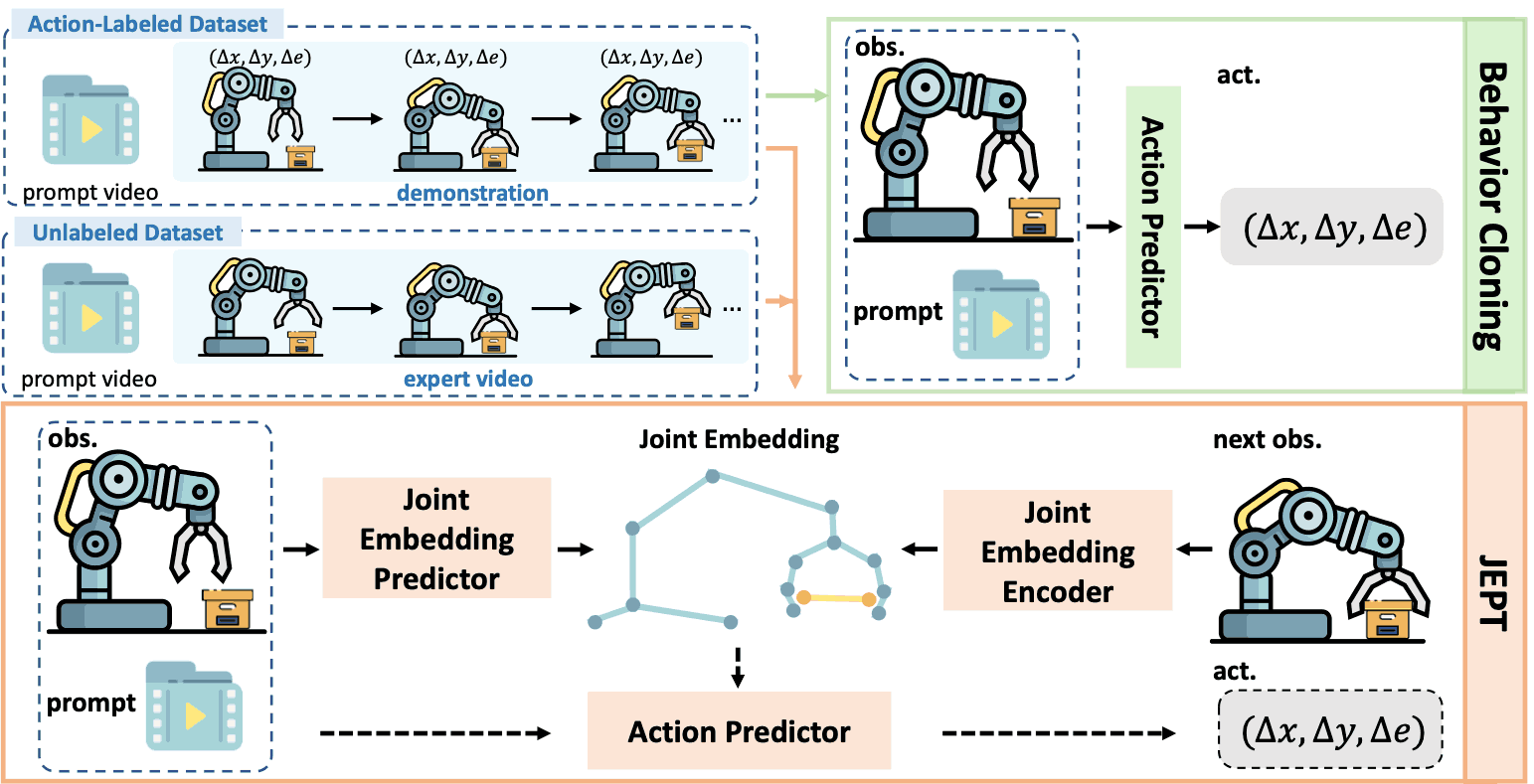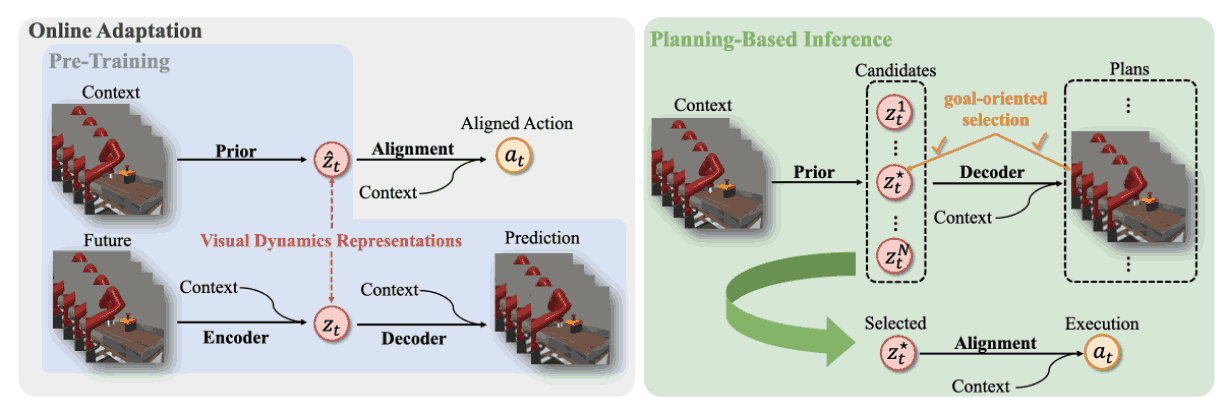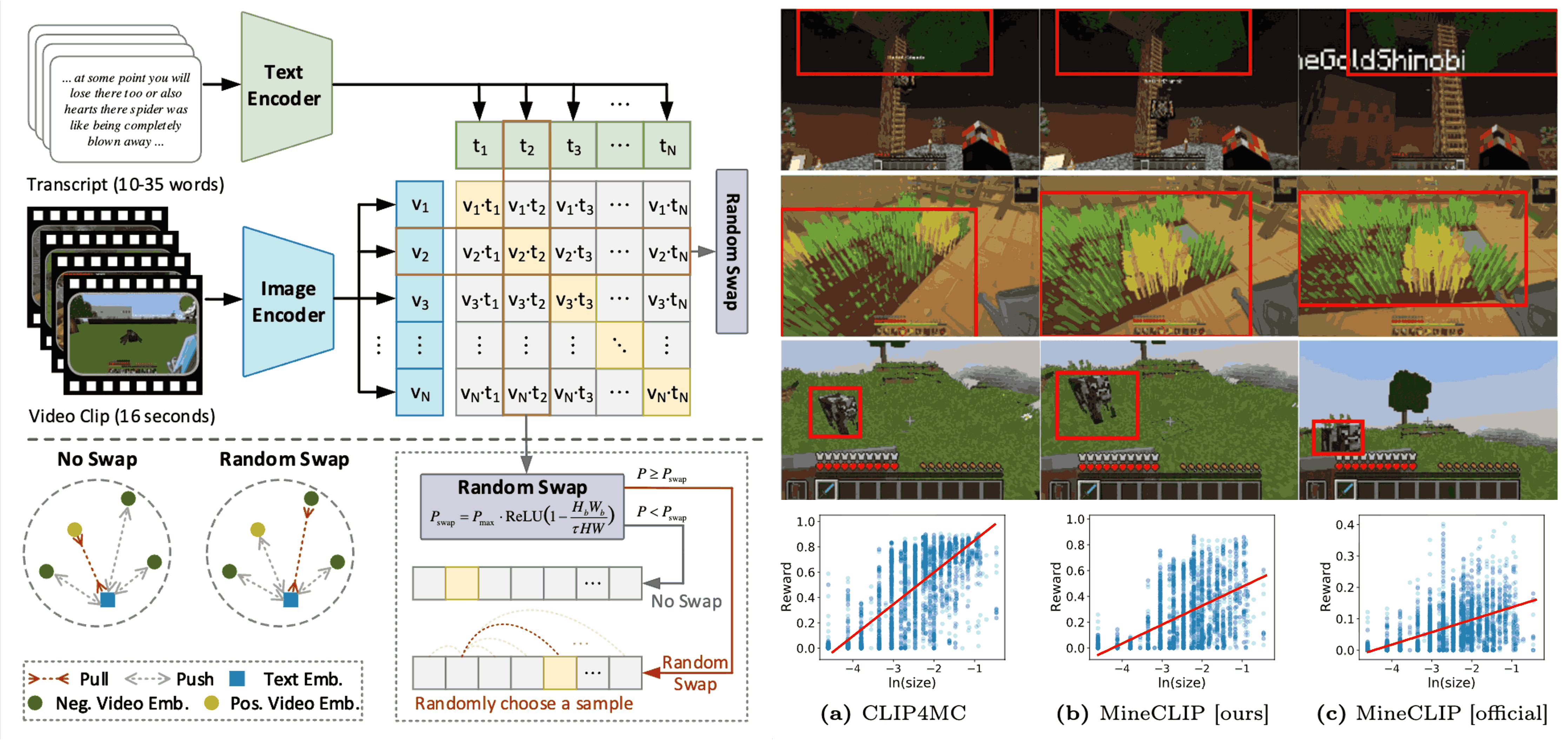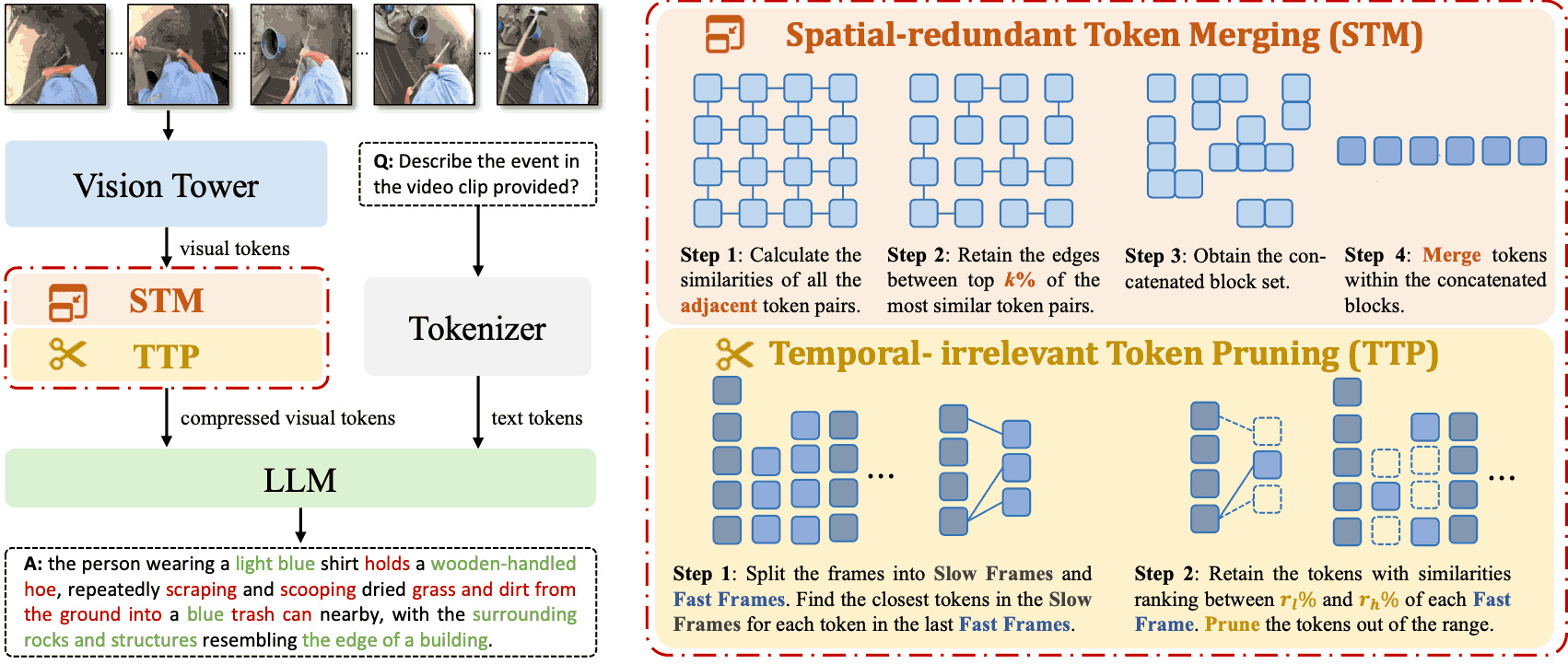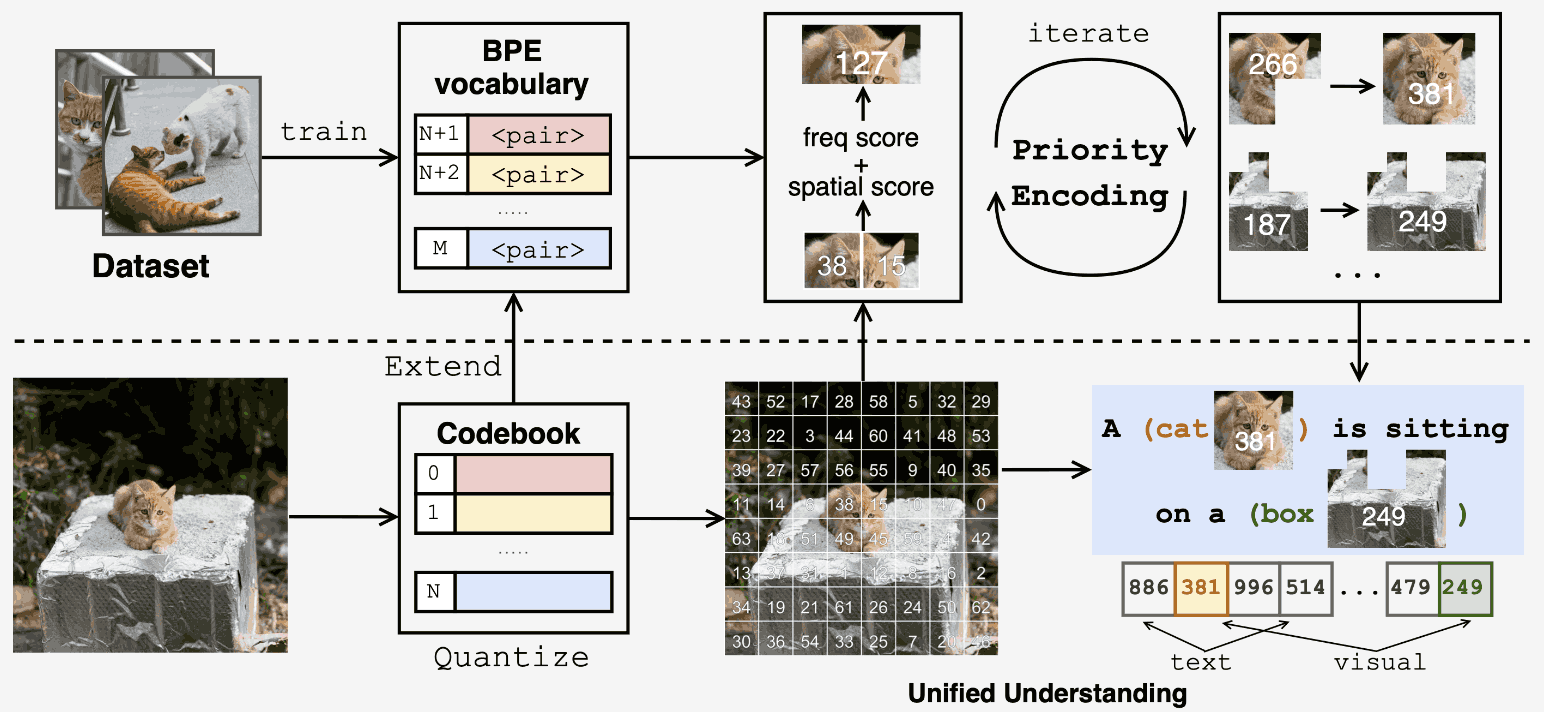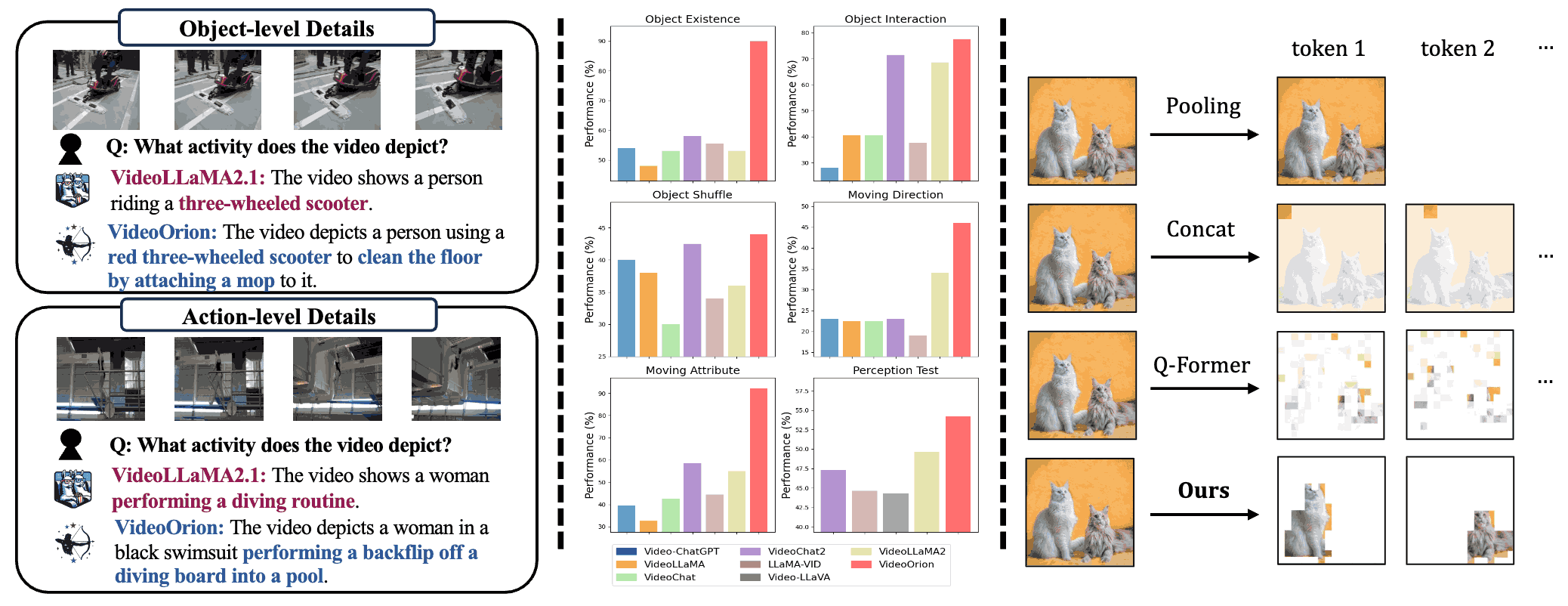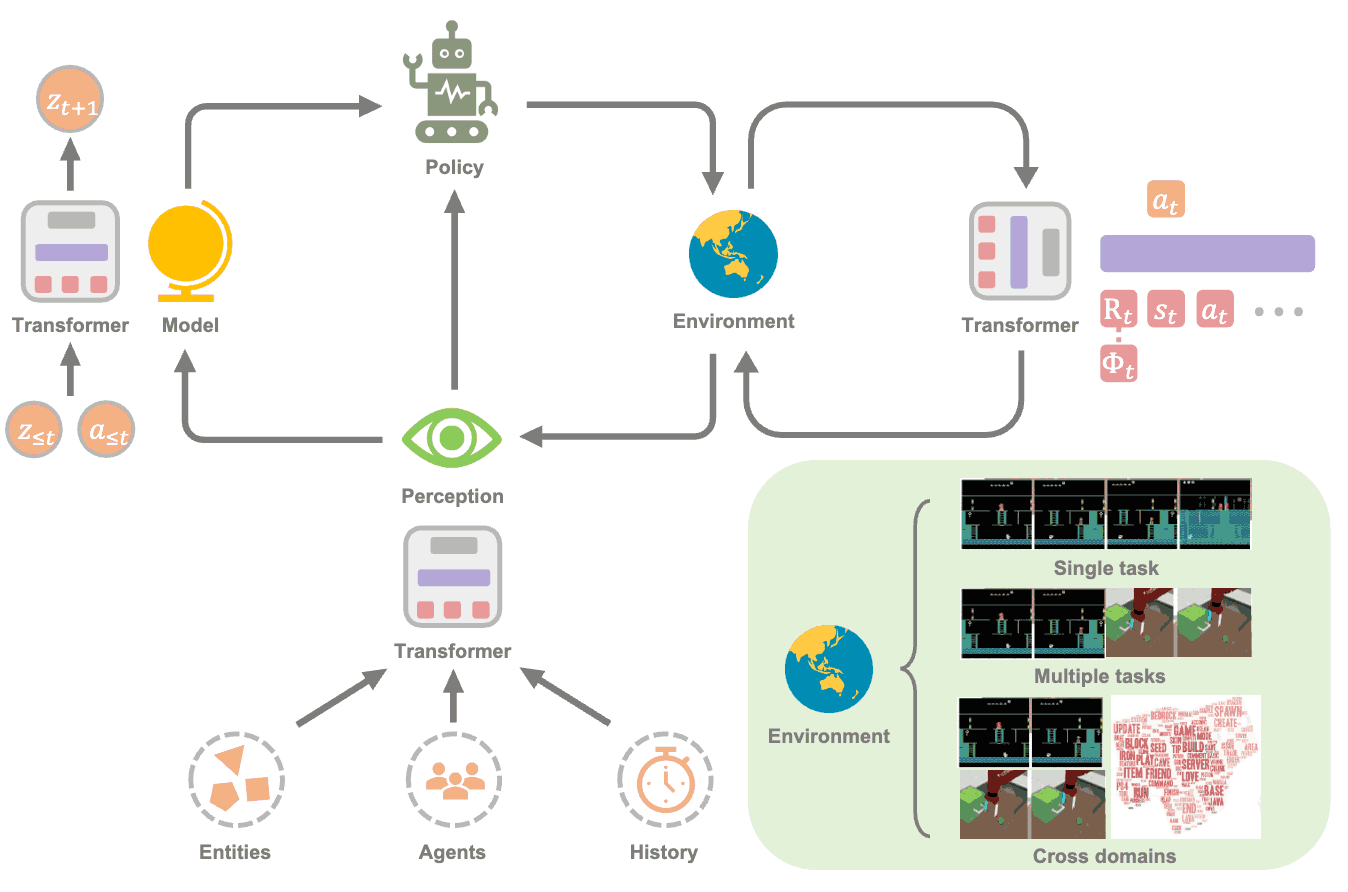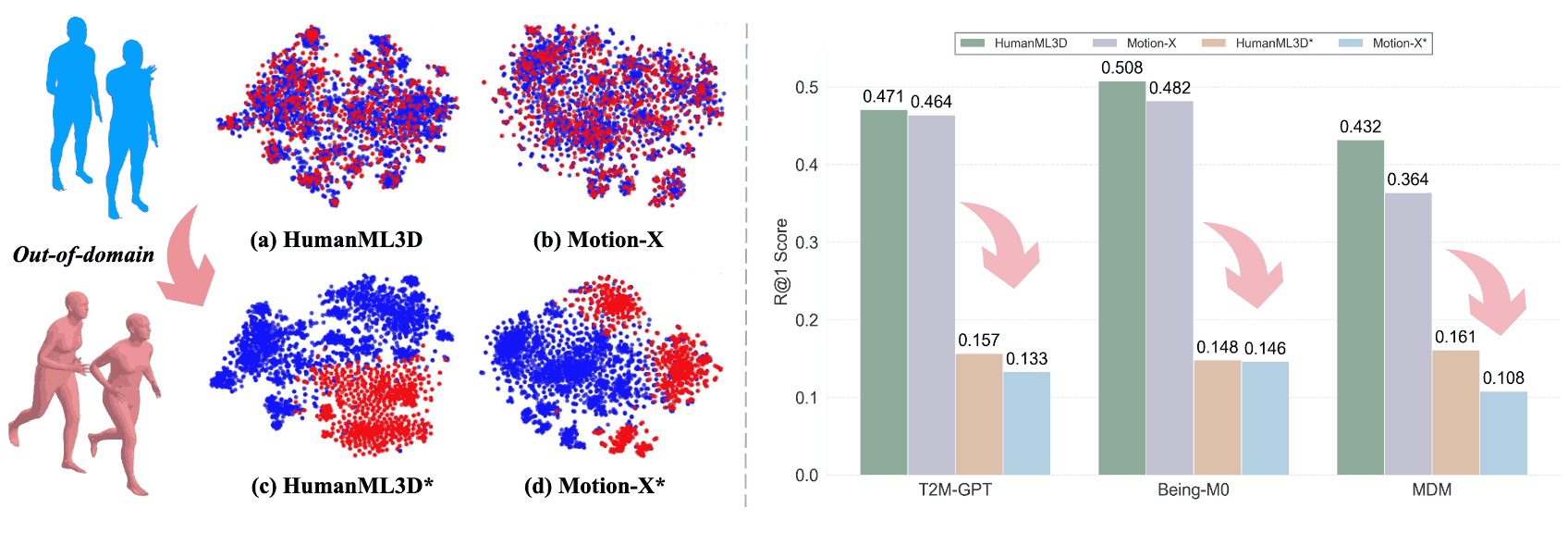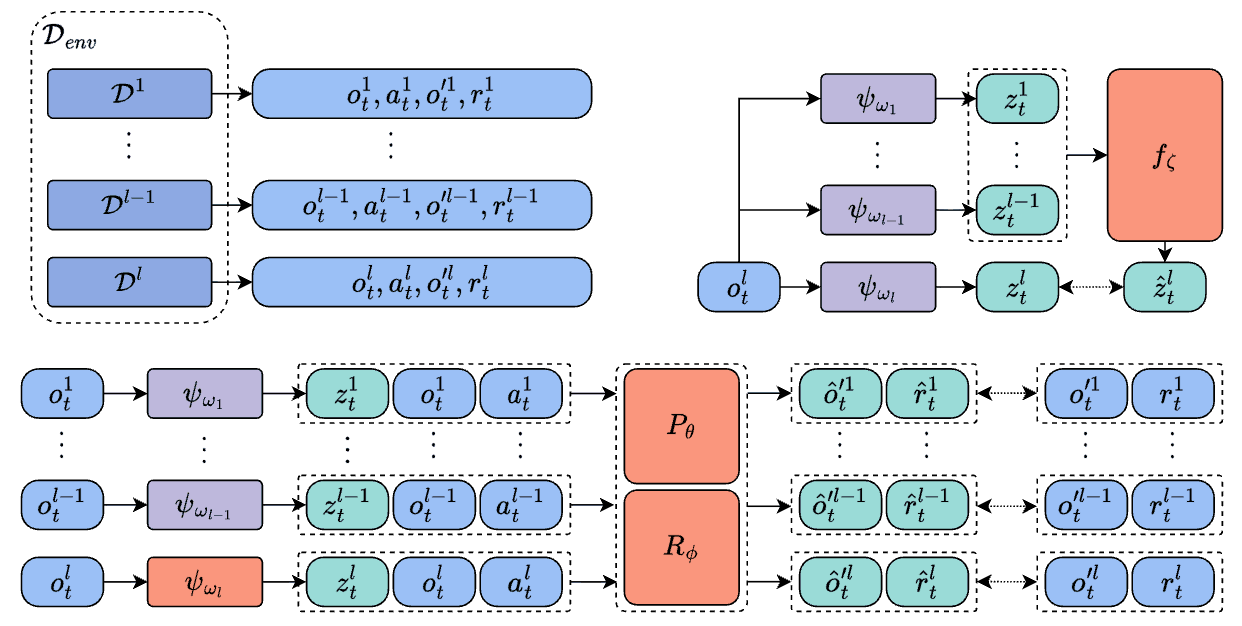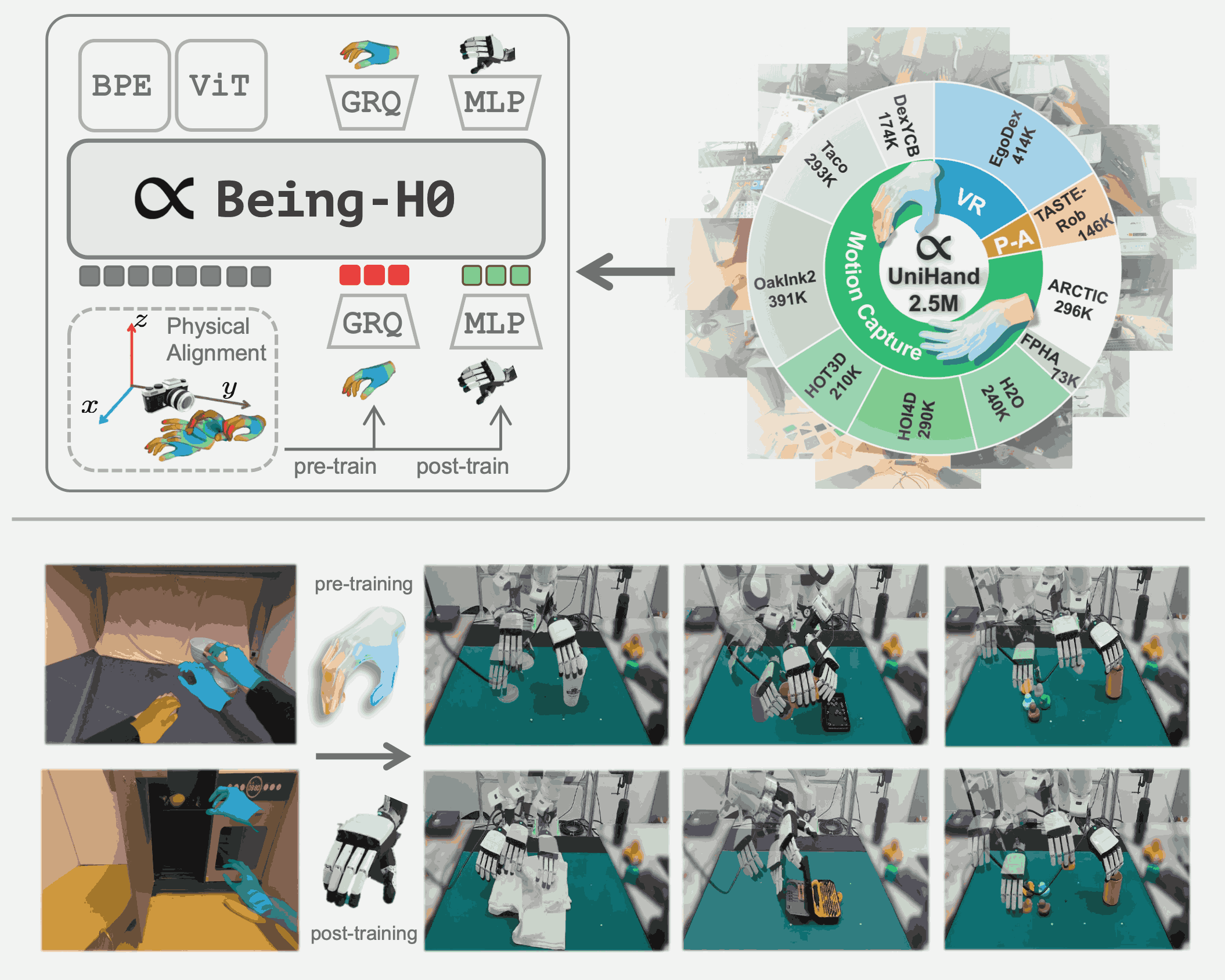
Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos
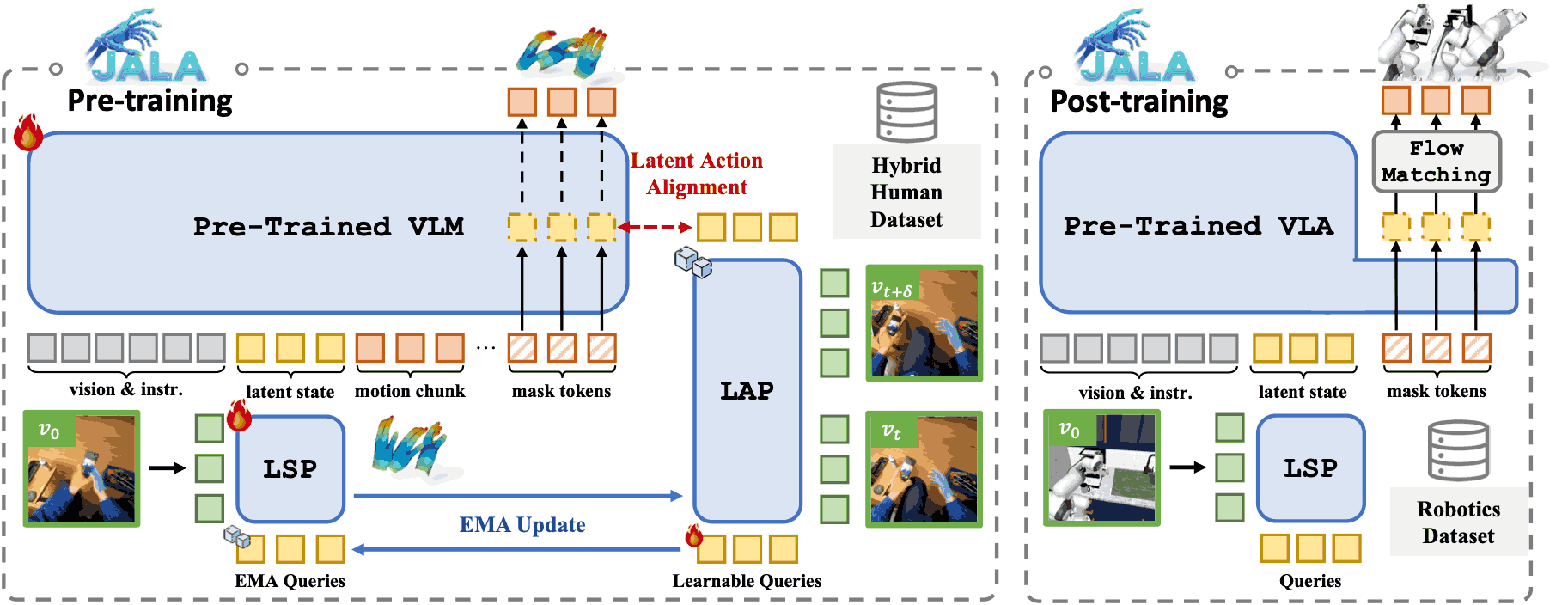
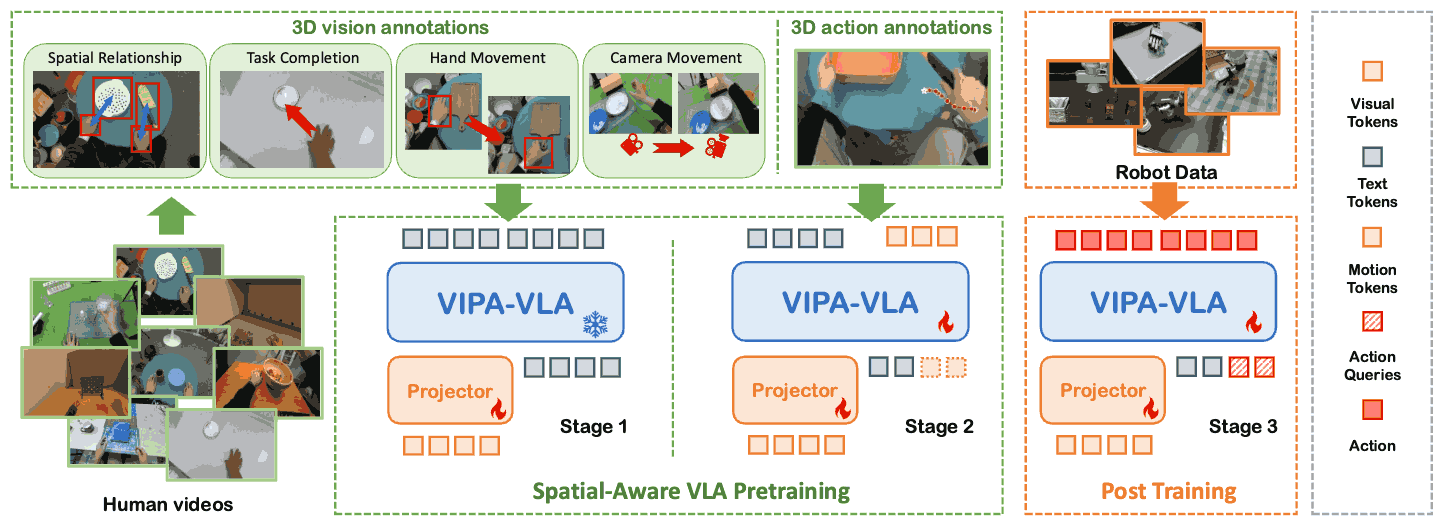
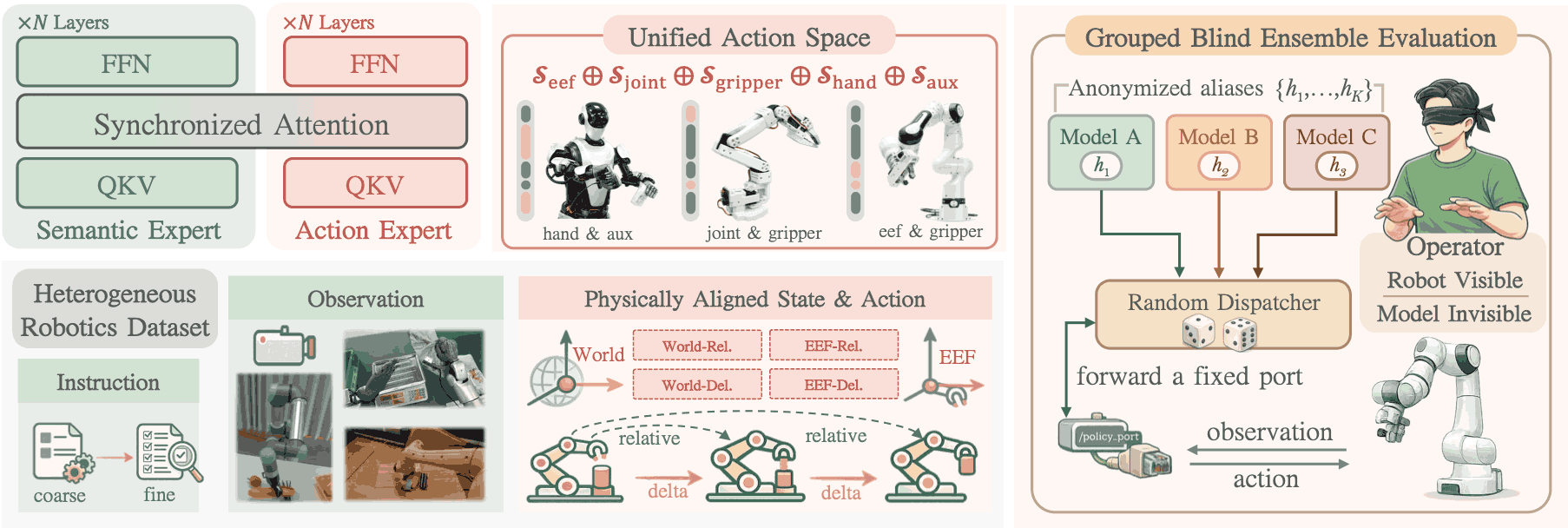
Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the UniHand dataset via physical instruction tuning. By explicitly modeling hand motions, the resulting foundation model seamlessly transfers from human hand demonstrations to robotic manipulation.